ML — это инструмент, при помощи которого решается определенный класс задач.
Прежде чем рассмотреть основные типы задач, которые решают алгоритмы машинного обучения, рассмотрим следующий пример, чтобы понять, почему эти задачи нельзя решить (или так эффективно решать) при помощи других известных методов.

Допустим вы хотите иметь программу, которая, получив на вход фотографию фрукта, могла бы сказать: это яблоко или мандарин? (Вместо яблока и мандарина может быть как раковая опухоль на рентгеновском снимке, так и определение мошеннических транзакций).
1) Самый простой способ решить эту проблему — посадить человека с хорошим зрением, который подписывал бы полученное фото. Очевидно, что такой подход имеет свои недостатки:
a. Человек может устать, не выйти на работу
b. Человеку нужно платить зарплату, оформить страховку, ему нужно искать замену, когда он захочет в отпуск
c. Человек (в сравнении с компьютером) достаточно медленно выполняет поставленную ему задачу
2) Тогда мы решаем вместо человека написать программу, которая бы решала нашу задачу. Мы даже соберём ведущих в мире экспертов по мандаринам и яблокам и попросим их описать программисту все возможные отличия этих фруктов друг от друга. В результате мы получим программу, которая на основании цвета фрукта, длины листа и продолговатости фрукта говорит нам — яблоко это или мандарин. Система работает какое-то время, до тех пор, пока нам не попадется яблоко с формой листа мандарина или яблоко красноватого (почти оранжевого цвета) как мандарин или же яблоко довольно круглой формы. Человек сразу увидит, что это яблоко, но наша программа скажет: “это мандарин!” Тогда мы снова соберём экспертов, обсудим, почему у нас здесь ошибка, добавим в программу еще ряд правил и так будет продолжаться каждый раз, пока мы не добьемся желаемого результата.
Минусы такого подхода:
a. Высокая стоимость разработки (оплата экспертов, программистов и тд)
b. Получившаяся программа будет очень сложна и объемна
c. Большие временные затраты на разработку
d. Невозможность сразу выловить все возможные зависимости в предметной отрасли, и описать все возможные случаи, различия.
3) Поняв, что варианты 1 и 2 нам не подходят, мы ищем альтернативные способы решения этой задачи и приходим к алгоритмам машинного обучения. Используя нужные алгоритмы машинного обучения, мы получаем программу, которая, обучившись на большом количестве фото яблок и мандарин, решает нашу проблему. Из минусов, необходимо большое количество размеченных данных (большое количество фото яблок и мандарин, к тому же ещё и отсортированных)
А теперь представим, что у нас не 2 фрукта, а 100, и тут у нас второй вариант становится совершенно нереализуемым. К тому же, это могут быть не фрукты, а распознавание раковых опухолей на рентгеновских снимках, детекция мошеннических действий с банковской картой, выявление спама в почте, распознавание речи т.д. Есть часть задач, решать которые попросту нерационально (а порой и невозможно) без участия ML.
Определившись с вопросом зачем нам нужен ML, разберем, для каких задач он подходит.
Основные задачи, которые решают алгоритмы машинного обучения — это те задачи, которые тяжело либо невозможно, либо нерационально решать непосредственным, “явным” (explicit) программным либо аналитическим способом. Среди этих задач (по типу решаемых проблем) можно выделить следующие 4:
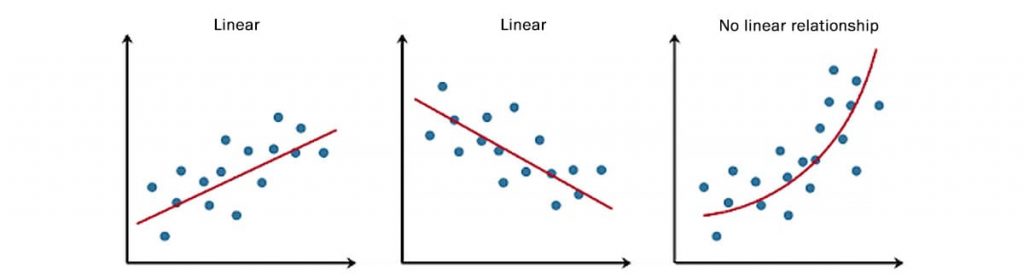
Регрессия — это задача предсказания значения непрерывной числовой величины для определенного объекта на основе его характеристик. Например, прогноз цен на рынке недвижимости, прогноз температуры, количество денег, потраченных в магазине клиентом, и т.д..
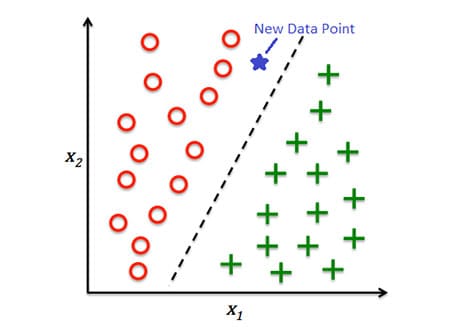
Классификация — это задача прогнозирования категориального признака, к которому принадлежит объект. Например, категоризация входящих писем на спам и не спам, задача кредитного скоринга, классификация изображений и т.д..
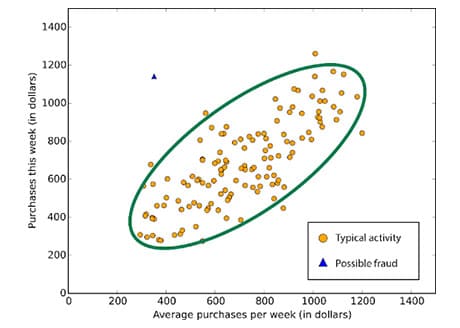
Детекция аномалий — это задача идентификации элементов, событий или наблюдений, которые не соответствуют ожидаемому шаблону или другим элементам в наборе данных. Примерами такой задачи могут быть: детекция мошенничества, детекция отказа работоспособности системы, поиск ошибок в тексте и т.д..
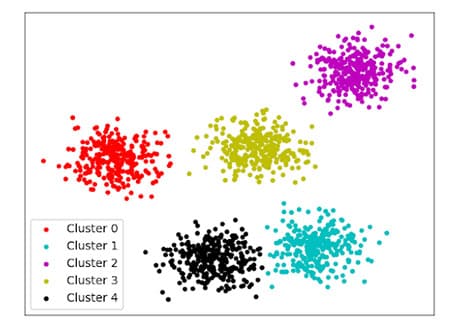
Кластеризация — это задача автоматической группировки похожих между собой объектов в кластеры. В отличии от задачи классификации, мы заранее не знаем информацию о количестве кластеров и о том, к какому кластеру (к какой группе) принадлежат объекты в тренировочном датасете.
Что такое AI, ML и Data Science? Машинное обучение (ML). Часть 2Итак, мы продолжаем цикл статей о AI и ML, для начала приведем ключевые определения.
Что такое AI, ML и Data Science?
Давайте попробуем дать ответ на вопрос: “что такое ИИ, ML, Data Science и чем они отличаются?”
Чаще всего под термином Искусственный интеллект мы подразумеваем, что это некая система (абстракция), обладающая свойствами интеллекта человека, которая может мыслить, решать задачи (в том числе творческие), которые подразумевают наличие мыслительного процесса для его выполнения. Пожалуй, самое важное, что нужно знать — искусственного интеллекта, который описан выше, на данный момент, не существует. Слишком сложен наш мозг и сознание в целом для того, чтобы их оцифровать или сделать математическую модель, копирующую работу нашего сознания. Однако, существуют попытки (в том числе довольно удачные) имитации деятельности нашего мозга для решения тех или иных задач. Одним из направлений в ИИ, подпадающим под такую формулировку, является Machine Learning (ML).
Прежде чем перейти к ML, дадим более строгое определение для ИИ.

Искусственный интеллект, ИИ (Artificial Intelligence, AI) — инженерно-математическая дисциплина, занимающаяся созданием программ и устройств, имитирующих когнитивные (интеллектуальные) функции человека, включающие, в том числе, анализ данных и принятие решений.
Сильный ИИ/Человекоподобный ИИ (Strong AI, Super‑AI) — интеллектуальный алгоритм, способный решать широкий спектр интеллектуальных задач, как минимум, наравне с человеческим разумом.
Слабый ИИ/Специальный ИИ (Narrow AI, Weak AI) — интеллектуальный алгоритм, имитирующий человеческий разум в решении конкретных узкоспециализированных задач (игра в шахматы, распознавание лиц, общение на естественном языке, поиск информации и т.п.).

Машинное обучение — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение за счёт опыта решений множества сходных задач. Для построения таких методов используются средства математической статистики, численных методов оптимизации, математического анализа, теории вероятностей, теории графов, а также различные техники работы с данными в цифровой форме.
Допустим, у нас есть алгоритм, который позволяет торговать на бирже. Он не знает о существовании биржи, трейдеров, брокеров и т.д. — это просто мат модель, которая обучена торговать на сотнях тысяч примеров. Аналогично, алгоритм, который водит беспилотный автомобиль, понятия не имеет о том, что такое автомобиль, дорога, двигатель, как он работает, и так далее. Алгоритм обучен на большом количестве примеров как решать ту или иную задачу, но не владеет способностью выходить за рамки сформулированной заранее задачи.
Алгоритмы машинного обучения — это программная реализация той или иной мат модели. Эта модель, на основании большого количества данных, “учится” решать ту или иную задачу, находя нужные закономерности в данных. Именно машинному обучению и принципам его работы и реализации его в проектах и будет посвящена основная часть этой статьи.

Data science — это обобщённое название отрасли, вида профессии, в которой основной упор делается на работу с данными. Дата Сайентистом может быть как человек, работающий с базами данных, или человек, разрабатывающий алгоритмы машинного обучения, так и человек, обслуживающий инфраструктуру, предназначенную для работы с данными.
Data science — это такое же обобщённое понятие, как и Сomputer science.
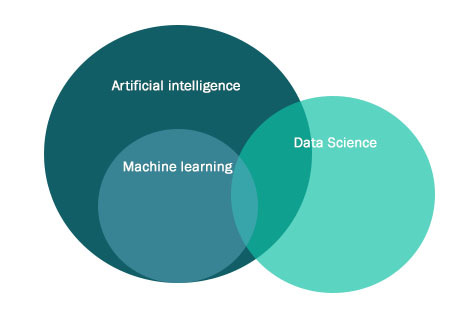
Теперь, разобравшись в терминах, остается вопрос: “А зачем нужен ML?”
Продолжение и ответ на этот вопрос читайте в следующей статье (часть 3)…
AM-BITS при поддержке Cloudera — Технологический партнер конференции UAFIN.TECH 2021Приглашаем наших друзей и знакомых на совместную презентацию представителей AM-BITS и Cloudera во время конференции UAFIN.TECH 2021, которая состоится 8 декабря в КВЦ «Парковый». UAFIN.TECH 2021 – это уникальная концентрация ведущих экспертов, инвесторов, банкиров и топ-менеджеров крупнейших компаний. Совместный доклад состоится в потоке «Будущее технологий».
Впервые в Украине, вживую, представители компании Cloudera будут рассказывать о новейших тенденциях и вместе с CEO AM-BITS, Евгением Манжуляновым, поделятся опытом и успешными кейсами в финансовой сфере.
Напомним, что AM-BITS – единственный партнер Cloudera в Украине со статусом Cloudera Silver Partner, подтверждающий наличие экспертной команды и опыта.
До встречи!
————
Cloudera – американская компания, разработчик наиболее полного и всеобъемлющего комплекса программных продуктов для работы с большими данными. Комплексная платформа предоставляет инструменты для работы с данными на каждом этапе жизненного цикла данных и обеспечивает все требования по работе с чувствительными данными, включая безопасность данных, управление данными, машинное обучение, аналитику и т.д. Все инструменты оптимизированы для облачной и гибридной инфраструктуры. 9 из 10 крупнейших банков мира работают с Cloudera.
Машинное обучение (ML). Часть 1Вступление
Сейчас термин машинное обучение можно услышать буквально на каждом шагу. ML крепко занял свое место как в новостных трендах, так и на рынке труда и в сфере автоматизации. Отовсюду доносятся истории успешного внедрения “Искусственного Интеллекта” в те или иные процессы компаний, а профессия data scientist обретает титул “The Sexiest Job of the 21st Century”.
При этом, несмотря на огромную популярность, ML остаётся довольно труднодоступной для комплексного понимания темой, в силу своей сложности, новизны, и высокой скорости роста (что порождает кучу мифов) и оставляет множество вопросов без ответа для людей, пытаются разобраться в этой теме.
Основная цель этой серии статей — доступным языком рассказать о том, что такое ML, где и как оно применяется, какие задачи решает, и развеять несколько мифов, связанных с этим термином, но самое главное — это познакомить с базовыми понятиями и концепциями, необходимыми для реализации своего ML проекта. В этой статье мы рассмотрим, что такое машинное обучение, дадим основные определения Machine Learning, узнаем из каких этапов состоит реализация ML проекта и какие задачи можно решать при помощи ML.
Мы начнём с основных понятий и будем постепенно углубляться в суть вещей, но сначала — рассмотрим следующий пример.

Допустим, есть агентство, которое перепродает автомобили, и существует потребность в программе, которая на основе информации об автомобиле может предсказать его стоимость на рынке (за сколько её можно будет перепродать). Компания хочет анализировать большое количество объявлений с различных сайтов объявлений и первой реагировать на выгодные объявления (меньше чем за секунду после того, как они появятся). Но в день появляется огромное количество объявлений на различных ресурсах, и отследить их вручную практически невозможно.
Для решения этой задачи мы хотим разработать программного помощника, который за нас перебирал бы объявления и находил подходящие нам. Он бы предсказывал цены на авто на вторичном рынке, и, если его цена выше, чем та, за которую мы можем это авто купить, — это объявление отправляется эксперту на рассмотрение. (Читать подробнее про кейс).
Тогда для решения задачи нам понадобится:
- Четко сформулировать задачу (построить алгоритм прогнозирования цены автомобиля на вторичном рынке на основе его свойств).
- Собрать имеющиеся у нас данные об автомобилях, хранящиеся на сайтах с объявлениями. На основе этих данных мы будем обучать алгоритм и строить прогнозы
- Сделать предобработку данных (привести данные в табличный вид, очистить, обогатить данные, обработать пропуски)
- Построить предиктивную модель
- Разработать программную инфраструктуру под эту задачу и интегрировать в нее наш алгоритм из пункта 4)
Реализовав эти шаги, мы получим программу, которая сама собирает объявления о продаже автомобилей с площадок объявлений, анализирует их и передает эксперту только те, что с большой вероятностью являются финансово выгодными.
Как видно, ML — это не волшебная палочка, которая сама по себе решает любую задачу, а комплексный инструмент, который также требуется правильно интегрировать, не говоря уже о процессе исследования и разработке самих ML алгоритмов.
Этот пример показывает, как можно использовать ML в автоматизации бизнес-процессов, а также, что более важно, этот пример демонстрирует основные пункты (1-5) разработки ML проекта. Следует учитывать, что несмотря на кажущуюся простоту, реализация ML проекта — это комплексная и довольно сложная задача. Чтобы получить более глубокое представление о том, что такое Машинное Обучение, — предлагаем ознакомиться со следующей статьей «Что такое AI, ML Data и Science?»
А пока что, можете ознакомиться с реализованными нашей командой ML проектами: https://am-bits.com/solutions/analytics-projects
Как мигрировать Hortonworks Data Platform на Cloudera Data Platform?Зачем мигрировать с HDP / CDH?
В 2019 году компания Cloudera презентовала новую платформу — Cloudera Data Platform, которая позиционируется как универсальное решение, позволяющее управлять данными в любой среде: Public Cloud, bare metal, Private Cloud, а также гибридное облако.
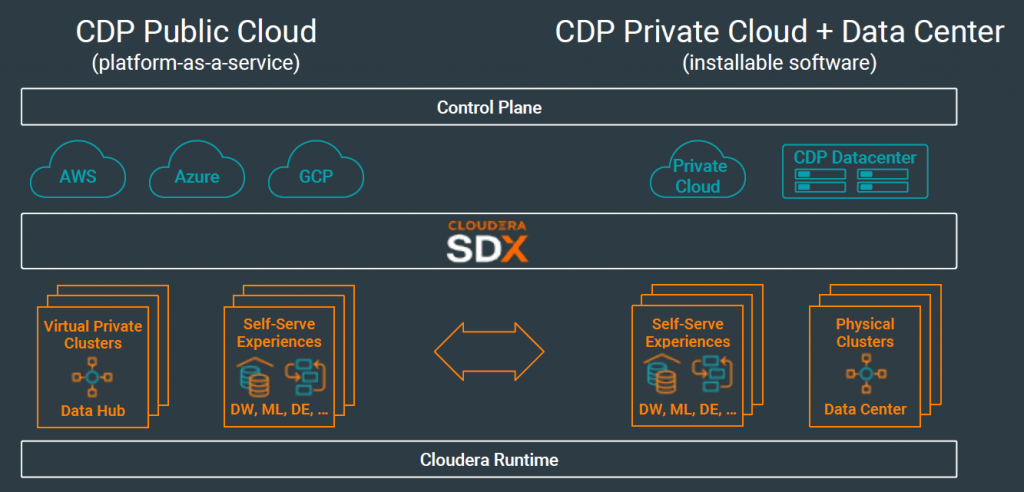
В соответствии с новой стратегией развития, презентованной главным техническим директором Cloudera по эксплуатации в регионе EMEA Яном Кунигком (Jan Kunigk),и старшим менеджером по инженерным решениям Cloudera в Германии, Австрии, Восточной Европе и России Флорианом фон Вольтером (Florian von Walter) – журнал “Storage News” № 1 (76), 2020 , развитие решений на базе Hadoop on premise является первым этапом, далее предполагается перенос мощностей в Public Cloud, и, в конечном итоге, в Hybrid Cloud.
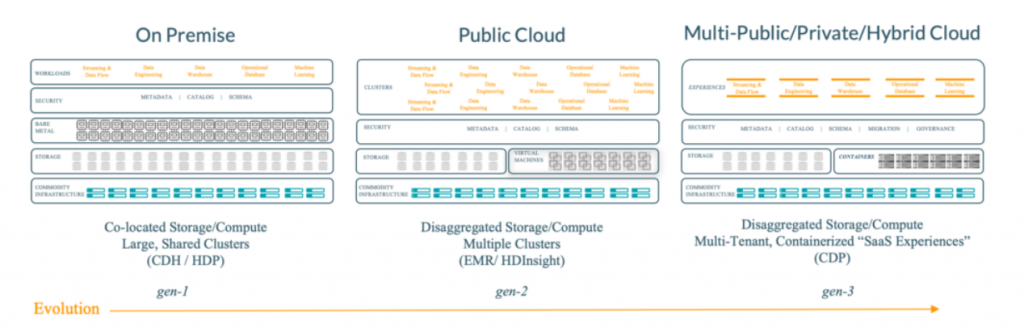
Учитывая новую стратегию Cloudera, рекомендуется мигрировать с платформ CDH – Cloudera Distribution of Hadoop и HDP – Hortonworks Data Platform на CDP, поскольку их поддержка будет прекращена после 31 декабря 2021, т.е., данные продукты не будет обновляться, и невозможно будет закупить техническую поддержку на решения на базе HDP, CDH. Это означает, что корпоративным клиентам, с целью сохранения функциональности своих решений, построенных на базе HDP, CDH необходимо провести миграцию на актуальный стек.
Почему CDP?
Мы рекомендуем пользователям HDP и CDH провести миграцию на Cloudera стек, поскольку Cloudera предлагает наиболее полный набор инструментов для работы с корпоративными данными:
- Cloudera Data Platform – платформа для организации сбора и хранения данных, для построения EDW, EDH
- EDGE & FLOW MANAGEMENT – для управления, контроля и мониторинга конечных устройств
- STREAMS MESSAGING – для доставки больших объемов поступающих данных в реальном времени.
- STREAM PROCESSING & ANALYTICS – для получения аналитических данных в режиме реального времени.
- DATA SCIENCE WORKBENCH — Обеспечивает возможность анализа данных, использование AI ML инструментов.
- Cloudera Manager — подсистема управления кластером.
- Cloudera также предлагает полный перечень инструментов, которые покрывают задачи, связанные с Data Security, Data Management, Data Governance.
- Для решений Cloudera доступна полноценная техническая поддержка от вендора.
Сравните функции и компоненты рассматриваемых платформ.
Важным изменением политики вендора является отсутствие бесплатного дистрибутива CDP в свободном доступе. В то же время, дополнительные функции и инструменты превращают Cloudera стек в самый удобный и экономически эффективный инструмент для построения решений на базе Hadoop на корпоративном уровне.
Подготовка к миграции
Cloudera предоставляет подробные инструкции по организации процесса миграции, предполагается несколько сценариев:
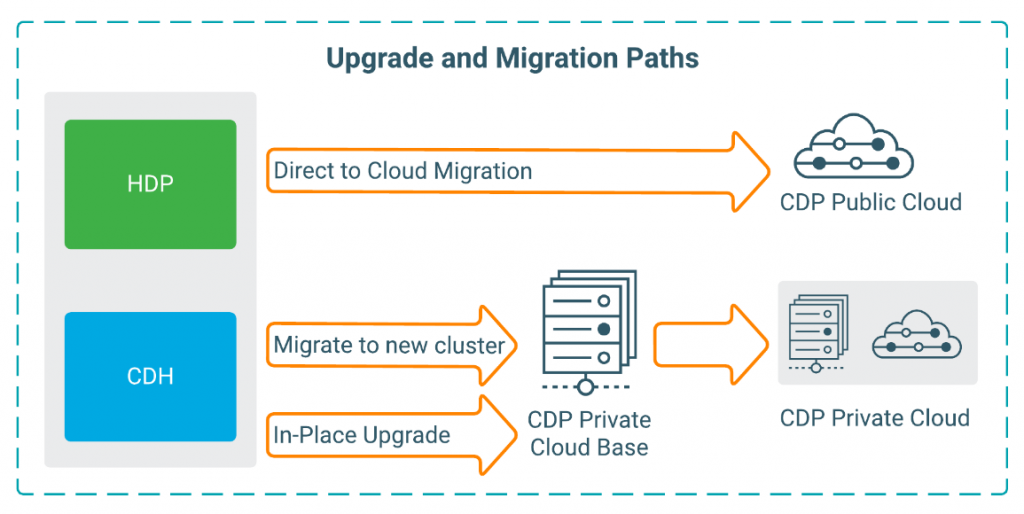
Для скачивания доступны пробные версии CDP для различных сред:
- 48-часовый тест-драйв платформы Cloudera в облаке
- бесплатная пробная версия CDP Private Cloud для ознакомления и тестирования
- также доступен CDP Upgrade Advisor , где собраны подробные рекомендации по отдельным кластерам.
Процесс интеграции
- Определите свой вариант миграции CDP: полное обновление или миграция с учетом требований к безотказной работе.
- Проверьте требования к обновлению и выполните все предварительные условия.
- Определите целевую среду:
- CDP Public Cloud Cloudera рекомендует для систем до 50 нод:
- CDP Private Cloud Cloudera рекомендует для систем свыше 50 нод:
- CDP on premise рекомендуется для заказчиков, которые в силу требований законодательства или внутренних корпоративных политик не рассматривают вариант миграции в облако.
- Установите, перенесите, протестируйте и подтвердите.
Пример плана миграции:
1.
Миграция DEV окружения со стека Hortonworks (HDP/HDF) на стек Cloudera (СDP/CDF)
2 недели
1.1
Очистка тестового окружения и подготовка требований к инфраструктуре и безопасности.
1.2
Инсталляция и конфигурирование CDP DEV Environment
1.3
Перенос разработок и данных из HDP/HDF DEV Environment в CDP DEV Environment
1.4
Тестирование и тюнинг окружения CDP DEV Environment
2.
Расширение кластера TEST и миграция со стека Hortonworks (HDP/HDF) на стек Cloudera (СDP/CDF)
2 недели
2.1
Очистка HDP/HDF DEV Environment
2.2
Инсталляция и конфигурирование CDP TEST Environment
2.3
Перенос разработок и данных из CDP DEV Environment в CDP TEST Environment
2.4
Тестирование и тюнинг окружения CDP TEST Environment
3.
Построение кластера PROD на стеке Cloudera (СDP/CDF)
3 недели
3.1
Очистка HDP/ HDF PROD Environment
3.2
Инсталляция и конфигурирование CDP PROD Environment
3.3
Перенос разработок и данных из HDP/HDF Prod Enviroment в CDP PROD Environment
3.4
Тестирование и тюнинг окружения CDP Prod Environment
Компания АМ-БИТС является прямым партнёром Cloudera (Silver Partner) и имеет выделенную Big Data команду из 15 высококвалифицированных архитекторов и инженеров, в числе которых 7 специалистов сертифицированных Hortonworks и Cloudera. АМ-БИТС имеет 5 лет опыта по построению Big Data решений на базе технологий Hadoop для корпоративных клиентов (включая проекты для международных банков, телеком операторов и медиа компаний).
Мы готовы разработать стратегию развития корпоративной платформы данных с учётом лучших международных практик и реализовать проект по миграции или внедрению Cloudera Data Platform, обеспечив бесперебойную работу сервисов, а также, по завершению проекта миграции/внедрения, обеспечить техническую поддержку решения как в удалённом режиме так и on-site.