ML is a tool for solving a specific class of problems.
Let’s consider the following example to understand the main types of problems that machine learning algorithms solve, and why such issues are unsolvable (or hard to be solved efficiently) using explicit methods.

For example, we need a program that defines a photo of fruit as an apple or a tangerine. (Alternatively, designing a program that has to recognize a malignant tumor on an X-ray image, detect fraud, etc.)
1) The obvious way to solve this task is to get a person (an employee) with good eyesight to label the given photo. Clearly, this approach has its drawbacks:
a) The employee may get tired, sick, or skip work for some other reason
b) The employee needs to get paid, provided with insurance and a replacement during vacation
c) A person (in comparison with a computer) is rather slow in decision making
d) Humans make mistakes
2) Consequently, we decided to write a program that would solve our problem instead of a person. We could even gather the world’s leading experts on tangerines and apples to describe all the possible ways to differentiate these fruits from each other. As a result, we would get a program that, based on the color of the fruit, the length of the leaf and the oblongness of the fruit, tells us whether it is an apple or a tangerine. The system could work fine for a while until we come across an apple with a leaf similar in shape to a tangerine one, or a reddish apple (almost orange) like a tangerine, or a rather round-shaped apple. The human would immediately see that it is an apple, but our program would conclude: “This is a tangerine!” Then we would gather the experts again, investigate the problematic cases, add some rules to the program… The upgrading of the program in this fashion will happen from time to time until we achieve the desired result.
Cons of this approach:
a) High development cost (experts fees, programmers salaries, etc.)
b) The resulting program will be very complex and difficult to maintain.
c) Long development span
d) The inability to discover all necessary dependencies in the problem field at once, and to jointly describe all possible cases and differences
3) Understanding that options 1 and 2 are unsuitable for us, we look for alternative ways to solve this problem and turn to machine learning algorithms. Using suitable ML algorithms, we get a program that, after being trained on a large number of photos of apples and tangerines, can extract the necessary dependencies from the data and solve our problem.
Cons:
a) A large amount of labeled data is required (a large number of photos of apples and tangerines marked accordingly)
Now let’s imagine that we have not 2 but 100 types of fruits: in this case, option 2 (writing our software without using ML) becomes completely infeasible. Even more, much more complicated problems, rather than fruit recognition, are possible, which would in turn be more difficult to implement explicitly. For example, malignant tumor recognition on X-ray images, fraudulent activities with bank cards, spam detection, speech recognition, etc.. Some tasks are just irrational (almost impossible) to solve without the ML tools.
Having figured out why we need ML, let’s see what tasks it is suitable for.
The main tasks that machine learning algorithms solve are issues that are difficult or impossible or not rational to solve in direct, explicit software or in an analytical way. Among these tasks (according to the type of problems), the following 4 can be distinguished:
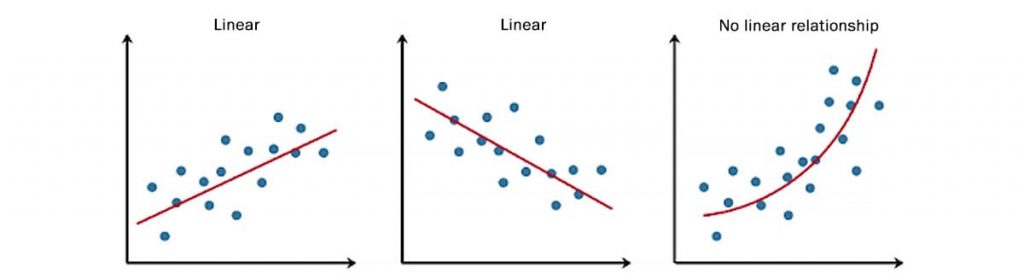
Regression is the problem of predicting a continuous numerical value for a specific object based on its characteristics. For example, the real estate market prices forecast, the temperature forecast, the prediction of the amount of money the client will spend in the store, etc.
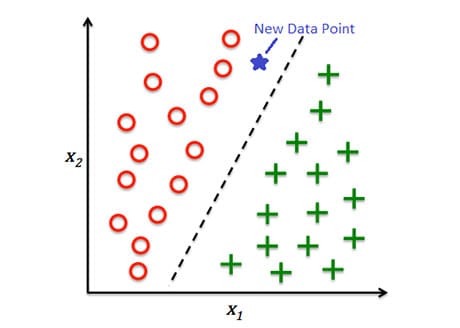
Classification is the task of predicting a categorical attribute of an object. For example, categorization of incoming emails into spam and non-spam, the task of credit scoring, image classification, etc.
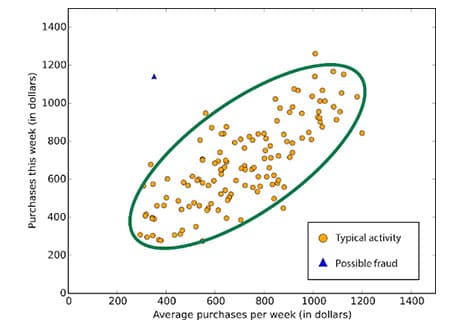
Anomaly detection is the task of identifying items, events or observations that do not match the expected pattern or other items in the dataset. For example fraud detection, system failure detection, discovering mistakes in a text, etc.
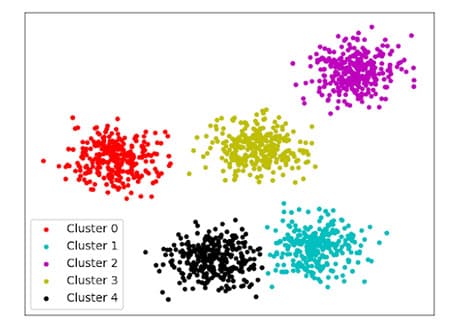
Clustering is the task of grouping similar objects into clusters. Unlike the classification problem, the number of clusters and which cluster (which group) the objects in the dataset belong to are not known in advance.
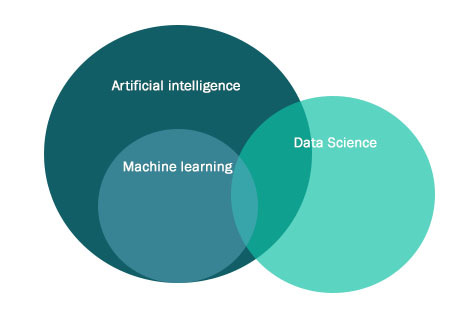
What is AI, ML and Data Science? Machine learning.Part2We continue the series of articles on AI and ML, let us first consider the definition and align what we mean under each term.
What is artificial intelligence (AI), machine learning (ML) and Data Science?
We will consider the question: “What is AI, ML, Data Science, and how do they differ?”
The term Artificial Intelligence is widely used and often understood as a kind of a system (an abstraction) that bears the properties of human intelligence, a system that can think, solve problems (including creative ones); these require the presence of a thought process in the implementation core of the system. Perhaps the most important thing to know is that artificial intelligence as described above does not exist in the present yet. Our brain and consciousness as a whole are too complex and not yet sufficiently studied to digitize them or make a mathematical model that mimics the working of our thought process. However, there are attempts (including quite fruitful ones) to imitate the activity of our brain in solving certain specific problems. A notable direction in AI that falls under this description is ML.
Before moving on to ML, let’s give a more rigorous definition of AI.

Artificial intelligence (AI) is an engineering and mathematical discipline that creates programs, devices and mathematical abstractions that simulate cognitive (intellectual) functions of a person, including, inter alia, data analysis and decision making.
Strong AI / Super-AI – an intelligent algorithm capable of solving a wide range of intellectual tasks, at least on a par with the human mind.
Narrow AI, Weak AI is an intelligent algorithm that imitates the human mind in solving specific highly specialized tasks (playing chess, recognizing faces, communicating in natural language, searching for information, etc.).

Machine learning definition
Machine learning is a class of artificial intelligence methods, designed to draw from data by learning through experience in solving many similar problems, instead of solving the problem directly. These methods are often driven by mathematical statistics, numerical optimization methods, mathematical analysis, probability theory, graph theory, as well as various techniques aimed at working with digital data.
Let’s say we have an algorithm that allows us to trade on an exchange. The algorithm does not know about the existence of the exchange, traders, brokers, etc. It is just a maths model that has been trained to trade on hundreds of thousands of examples.
Likewise, the algorithm that drives a self-driving car has no idea of what a car is, a road, an engine, how all these work together, and so on. The algorithm is trained on a large number of examples of how to solve a particular problem but does not possess the ability to go beyond the framework of a previously formulated problem.
Machine learning algorithms are software implementations of a particular maths model. This model “learns” to solve a particular problem on a large amount of data, to find the patterns in the data to solve a particular task. The main part of this article focuses on ML, the principles behind it and its implementation in projects.

Data science is a broad notion that stands for a field, a profession that focuses on working with data. Data Scientist can stand for a person, working with databases, or someone who designs machine learning algorithms, as well as someone who maintains data managing infrastructure.
“Data science” is as broad of a notion as, for example, “Сomputer science” is.
Now, after reviewing the key notions, a question cries out for an answer: “Why do we need ML?”.
We will consider this in the next part (part 3) of our article.
AM-BITS supported by Cloudera – Technology partner of the UAFIN.TECH 2021 conferenceWe would like to invite our friends and colleagues to the joint presentation of AM-BITS and Cloudera representatives during the conference UAFIN.TECH 2021, which will take place on March, 8 in Parkoviy Exhibition Center. UAFIN.TECH 2021 is a unique concentration of leading experts, investors, bankers and top managers of the largest companies. The joint discussion will take place in the stream “Future technologies”.
For the first time in Ukraine, live, representatives of Cloudera will tell about new trends and together with the CEO of AM-BITS, Mr. Manzhulyanov, will share their experience and successful cases in the financial sector.
We would like to remind you that AM-BITS is the only Cloudera partner in Ukraine with the status of Cloudera Silver Partner, which confirms the presence of an expert team and relevant experience.
See you there!
———–
Cloudera is an American company, the developer of the most complete and comprehensive set of software products for working with big data. The comprehensive platform provides tools for working with data for each phase of the life cycle of the data, and provides all the requirements for working with sensitive data, including data security, data management, machine learning, analytics, etc. All of the tools are optimized for a frictionless and hybrid infrastructure. 9 of the 10 largest banks in the world work with Cloudera.
Predictive Analytics: benefits and perspectives of the marketThe future of most commercial and noncommercial sectors is tightly connected with recent technological innovations. International corporations invest billions of dollars into Artificial Intelligence, Big Data, and Machine Learning solutions. This said, the sphere of Predictive Analytics (PA) serves as a catalyst for capitalizing on the recent innovations.
In 2019 the global PA market reached $7.32 billion, according to AMR research. The estimated value of the sector by 2027 is $35.45 billion – analysts expect 484% growth of the market. What is “Predictive Analytics” and why is the sphere important for today’s businesses?
Predictive Analytics: The notion and basic principles
If to start with “analytics”, the process is understood as the systematic numerical analysis of data and statistics to find some meaningful patterns, and the usage of these patterns for effective decision making. Driven by AI, Predictive Analytics is the second level in the analytics process hierarchy.
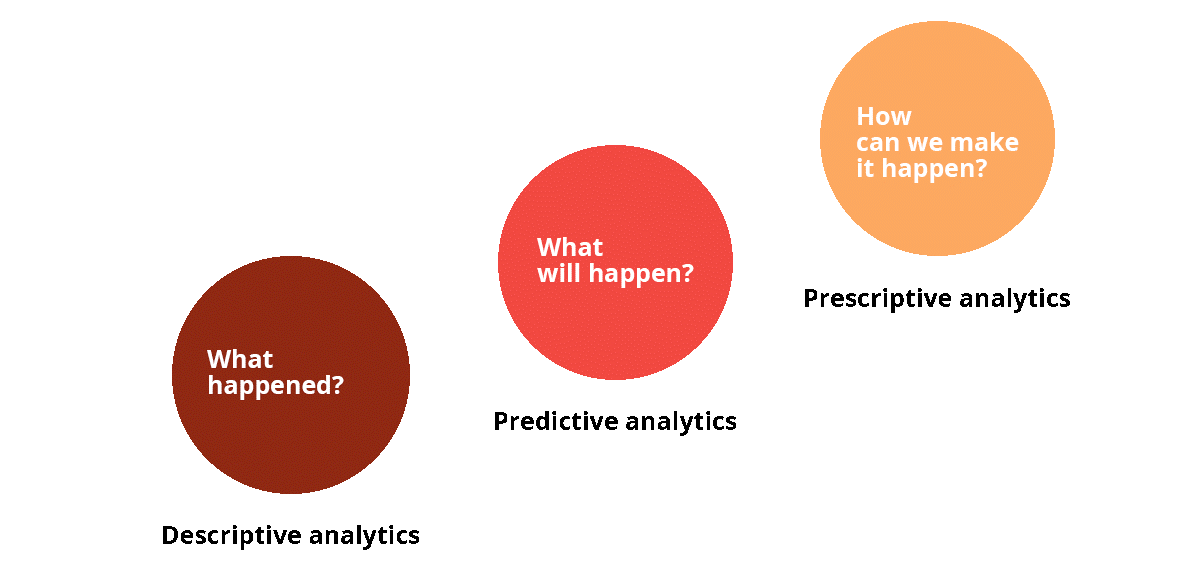
In simple words, PA mechanisms are responsible for predicting what will happen in the future within a certain field. Predictive Analytics is understood as a specific class of data analysis methods that relates to the prediction of objects/subjects’ future behavior models. The basic principles behind PA originate from the 1940s, but recent technologies like AI, Big Data, and ML have opened new horizons for PA practitioners.
The Predictive Analytics process is based on the four key constituents. The first two stages, formally speaking, precede the PA process, but doing analytics is impossible without them.
- Goal setting:
The goal setting stage together with hypothesis statement (the possibility to predict desired events on the basis of given data) lay the ground for the next steps.
- Data collection:
Data is the basis of every statistical analysis, including the Machine Learning approach. There are two critical characteristics which distinguish a successful data collection stage: data volume (dataset depth) and data quality. Big Data technology provides data practitioners with powerful instruments that make acquiring sufficient data volumes significantly more feasible.
- Exploratory data analysis:
Data itself is insufficient for making predictions. You need to implement appropriate approaches to discover interdependencies inside modern day data volumes. According to IDC, the annual growth of data being stored is 20.4%, and the total volume of data is expected to reach 8.9 zettabytes by 2024. Artificial Intelligence helps not get lost within such volumes of raw data by unraveling hidden correlations.
- Predictive modeling:
The closing chapter of the process is the recognition of data insights. This stage implies the construction of a mathematical predictive model to execute the necessary tasks. Machine learning technology utilization is the current trend at this stage.
Top benefits of AI-driven Predictive Analytics
Why do today’s businesses need to apply AI/ML analytics mechanisms to boost their profits? When your company is working on a new product or service, thousands (millions) of dollars are spent previously to analyze the market. Nevertheless, as a business owner, you need a precise answer whether your product/service will succeed or not.
Predictive Analytics gives business owners the following benefits:
● Higher market segmentation accuracy. The PA methods help sales managers build up a precise image of a target customer.
● The boost of conversion rates. The information of previous deals leads to finding potential customers more effectively.
● Increase in sales prediction efficiency. Based on accurate sales prediction, companies may plan their profits within a financial year.
● Customers clustering. PA methods allow business owners to divide customers set into sensible subsets, offering them more suitable goods and services.
● Hidden potential detection. Predictive Analytics helps companies create fertile ground for further development.
PA methods have many fields of application, commercial, non-profit or public, including.
- Healthcare. Automated predictive modeling may prevent chronic diseases and relapses on the basis of collected medical histories and information updates.
- Road safety and insurance industry. Predictive analytics may help customize vehicles for certain drivers, activate necessary settings and applications, and leverage a set of limits to prevent car accidents.
- Tourism sector. Such mechanisms may predict the increase or decrease of particular location popularity.
PA methods are effective in aiding decision-making in the fields of finance, weather forecasts, agriculture, and many others. The most popular modern day Predictive Analytics applications are within risk management, customer and financial analytics.
5 top open source use cases of Predictive Analytics: Brief overview
So, let’s take a sneak peek into several success stories in which harnessing the power of Predictive Analytics has brought about great results for business customers.
1. Delivering an ML-based algorithm for predicting NBA games results.
Challenge: A client needed an ML-based model to predict the chances of each team to win the next NBA game.
Strategy: The model was based on a recurrent neural network trained on a huge masses of NBA matches results.
Solution. The RNN-based model shows high forecast accuracy. The developers plan to test a model based on the temporal convolutional network, which provides image and video recognition to improve the forecast results.
Results. The current model accuracy is higher than 80%.
2. Ensuring AI-backed services for effective asset management.
Challenge: Catana Capital needed a highly effective service for accurate trading predictions and asset management.
Strategy: The service is based on the Big Data, AI, and Predictive Analytics methods, analyzing thousands of news, financial articles, blog posts, and other information to get the most complete picture of the market.
Solution: The service uses quotes from more than 45 thousand shares to get the most accurate forecasts of further price movements.
Results: As of now, this AI-driven Catana Capital service is in high demand among traders worldwide.
3. Implementing biometric verification based on voice data
Challenge: Call-centers needed an effective and secure authentication system, resistant to cyberattacks and expected to be convenient for users.
Strategy: The voice-based authentication system was set for further implementation. The system included the database of stored voice prints created to recognize speakers’ voices.
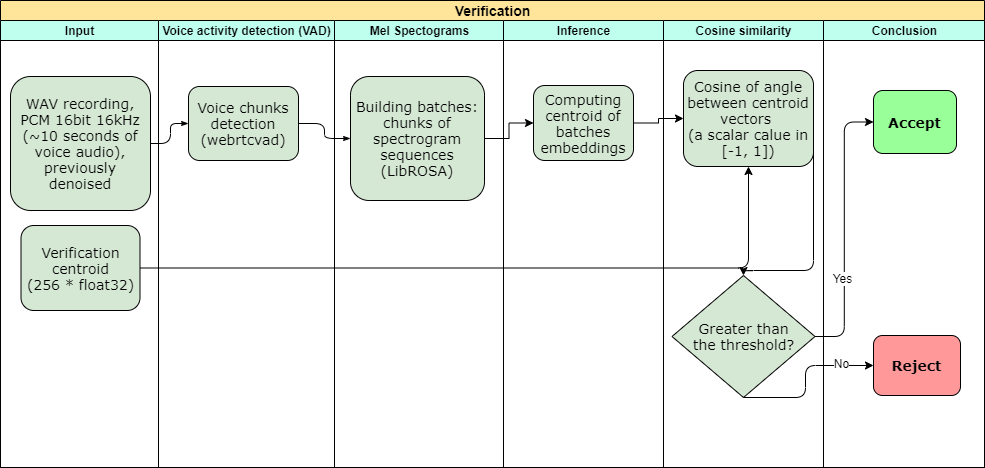
Solution: The system comprised a neural network to ensure that a certain voice corresponded with a stored voiceprint of a certain person.
Result: Business customers received the voice-based authentication system with high security to reduce the verification time and increase the authorization process efficiency. More…
4. Enabling cash flow optimization in ATM network system
Challenge: When operated manually or semi-automatically, the ATM network faced some significant hardships related to overly large expenses and imprecise monitoring results. The network required the estimation of the optimal amount of funds for cash collection.
Strategy: The PA methods were leveraged to predict the exact daily cash withdrawal amount and define the optimal cash flow.
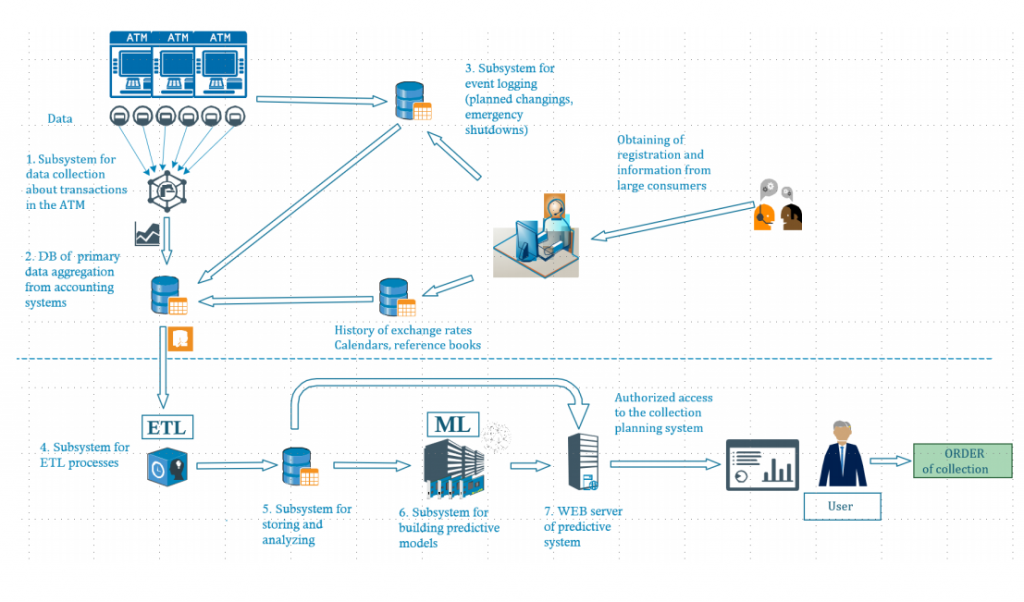
Solution: Based on the bank ATM data, the daily cash withdrawal amount was forecasted with maximum error indexes of 0.01-3.5% while utilizing cash flow Predictive Analytics algorithms.
Results: Cash use efficiency increased by 15-40%, and the downtime of ATM machines dropped to 0.2%. More…
5. Providing accurate forecasting of electricity consumption rates
Challenge: An energy company needed an effective, ML-based electricity consumption model. Furthermore, the task included building up a forecasting system that would enable a company to plan its purchase volume on the energy exchange.
Strategy: Recurrent neural networks were applied for building a forecasting system with the maximum preciseness index.
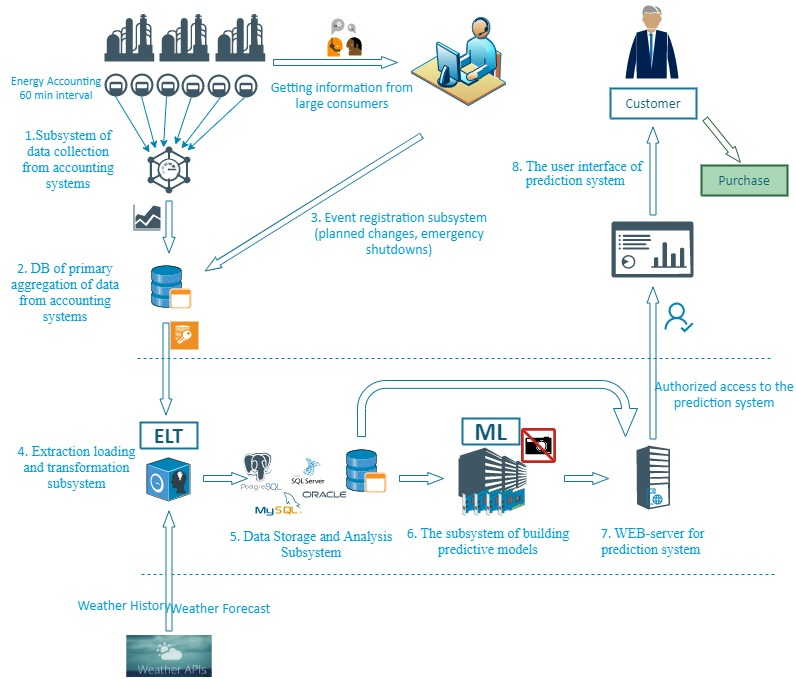
Solution: On the basis of open source New York City hourly energy consumption data and temperature fluctuation, the forecasting model for 2 days’ consumption rates was constructed.
Result: The forecasting ML-based system delivered to the business customer has a preciseness index of 96.4-99.5%. More…
Bottom line:
Predictive Analytics methods open up new vibrant horizons for business. Many companies start engaging necessary specialists in the field of PA, Artificial Intelligence, and other innovative technologies for implementing their internal business tasks. Usually, the most cost-effective solution is to hire a specialized company that has relevant expertise and enough specialists ready to develop and implement any complex all-in-one solution.
AM-BITS is a system integrator of BigData solutions. Our portfolio includes not only services based on Predictive Analytics but also solutions for building Enterprise DataHub, Streaming processing, Active Archive, and many others. We will be glad to discuss any tasks and projects for managing your corporate data and deliver the most relevant solution.
Machine Learning. Part 1
Introduction
The notion of machine learning is truly omnipresent nowadays. ML has firmly taken its place in the news trends, the job market and business automation. The success stories of “Artificial Intelligence” implementation are truly ample, and Data Scientist has become “The Sexiest Job of the 21st Century”.
That being said, despite its immense popularity, ML is still rather difficult to comprehend, due to its complexity, novelty, and booming growth (which gives rise to a bunch of myths), and there are plenty of open questions for people trying to understand this topic.
The main goal of this series of articles is to describe, in simple language, what Machine learning is, where and how it is applied, what tasks it solves, and to dispel several relevant myths, while the main intended takeaway is the basic concepts that are necessary for implementing a successful ML project.
In this part of the article, we will consider the question of what machine learning is, give basic definitions, list the stages that implementing an Machine Learning project consists of, and see what tasks can be solved using ML.
We will start with basic concepts and gradually delve deeper into the essentials, but first – let’s consider the following example.

Let’s consider an agency that resells used cars, and there is a need to predict its value on the market (resell price), based on given information about the car. The company needs to analyze a large number of ads from various sites in order to first respond to profitable offers (in literally less than a second after the proposal appears); however, since the number of ads per day on various resources is huge, it is almost impossible to track them manually.
In order to solve this issue, the company needs to develop a software assistant that would quickly grep through the ads and find suitable ones. It would predict the car prices on the secondary market, and if the expected market price for a particular car is higher than the proposal, the ad should be sent to an expert for consideration. (Learn more about case ).
To solve the problem is needed:
- Articulate the problem (to build an algorithm for predicting the price of a car on the secondary market based on the car properties).
- Collect the vehicle data, stored on ad sites. Based on this data, we will train the algorithm and make predictions.
- Do data preprocessing (bring data into tabular form, clean, enrich data, process missing data).
- Build a predictive model.
- Develop a software infrastructure for this task and integrate our algorithm from point 4 into it.
After implementing the above steps, we get a program that collects cars sale ads from ad sites, analyzes them and only sends the likely financially profitable ones for expert consideration.
As you can see, ML is not a magic wand that solves any problem out-of-the-box, but a complex tool that requires thoughtful integration, not to mention the process of researching and developing the Machine Learning algorithms themselves.
This example shows how ML can be used to automate business processes, and more importantly, it demonstrates the basic steps (1-5) of developing an ML project. It should be kept in mind that despite the seeming simplicity, the implementation of an ML project is a complex and rather difficult task.
So, let’s move to the further parts of this article to get a deeper understanding of what Machine Learning is.
We offer you to read the implemented ML projects by AM-BITS: https://am-bits.com/solutions/analytics-projects